Building Interoperable Geospatial Web Services with Uncertainty Metadata
OGC web service standards provide a foundation for composable geospatial processing, but do not natively encode uncertainty. Extending them with structured uncertainty profiles enables end-to-end propagation across multi-service environmental modeling chains.
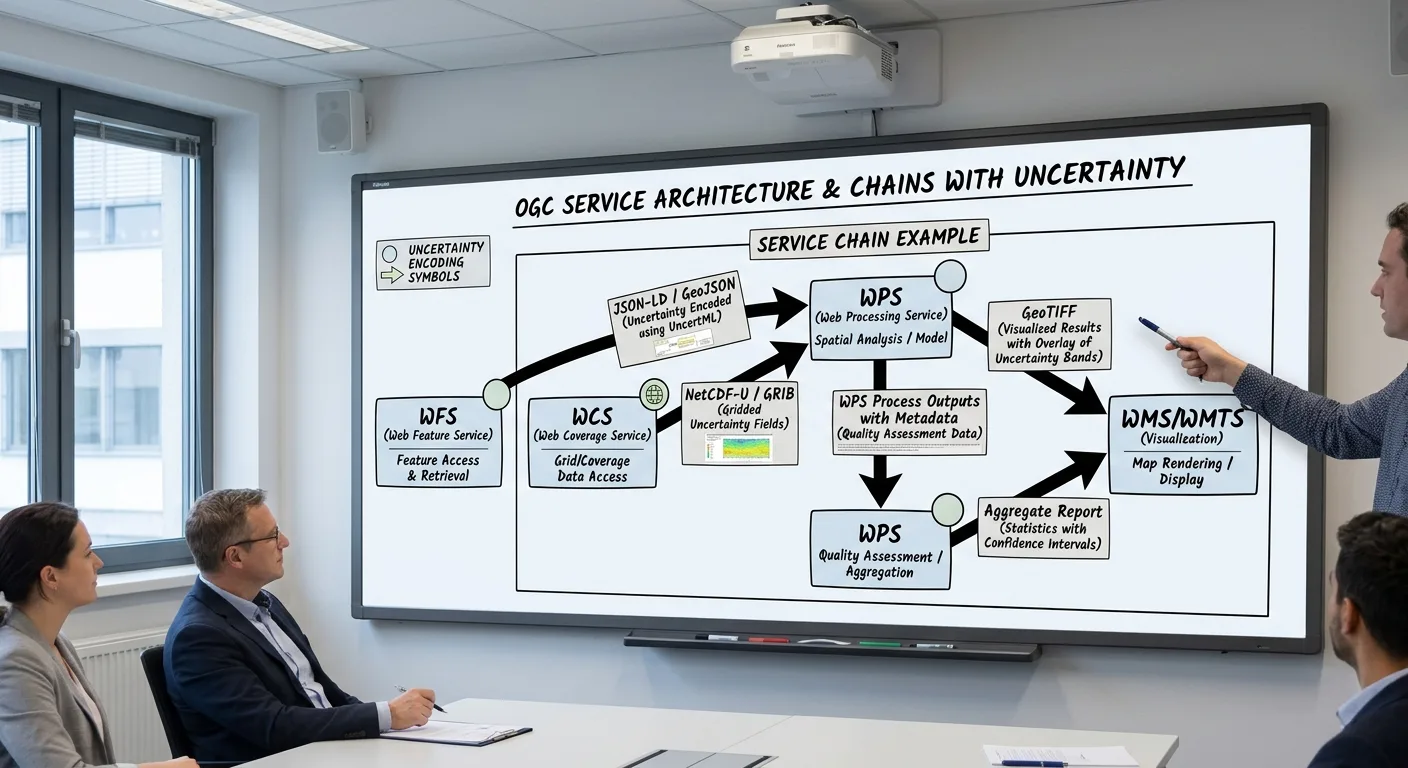
The geospatial community has invested decades in open service standards (OGC’s Web Processing Service, Web Feature Service, and Web Coverage Service among them) designed to make spatial data and processing accessible across organizational and technological boundaries. These standards largely succeed at their primary goal: a client that speaks the protocol can request a dataset or trigger a computation without knowing anything about the server’s internal software stack.
What the base standards do not address is uncertainty. A WCS coverage response returns a grid of values; the protocol has no native mechanism for accompanying each cell with an estimate of how uncertain that value is, or for a WPS process to declare that its outputs carry a certain type and magnitude of uncertainty. This gap is consequential when services are chained together in a processing pipeline. Uncertainty generated at the first step is invisible to every subsequent step, producing outputs whose nominal precision is higher than the data can support.
The Service Chain Problem
Consider a representative earth observation workflow:
- A land-surface temperature (LST) retrieval service ingests raw thermal infrared radiance from a satellite archive and applies an atmospheric correction algorithm to produce per-pixel LST values.
- A spatial aggregation service averages those LST values over administrative boundaries to produce regional summary statistics.
- A model service ingests the regional LST statistics alongside other climate variables to project vegetation stress indices.
At each boundary, the output of one service becomes the input of the next. If the LST retrieval service produces per-pixel uncertainty estimates (derived from atmospheric correction residuals and sensor calibration uncertainty) but has no standardized way to attach them to its output coverage, those estimates are discarded at the first service boundary. The aggregation service treats all LST values as equally precise, and the vegetation stress model has no basis for expressing confidence in its projections.
This is not a theoretical problem. It describes the routine state of most operational earth observation processing chains in use today. Uncertainty information is generated (implicitly or explicitly) at the sensor level, discarded somewhere in the processing stack, and then re-estimated (often poorly) at the final stage when a quality flag or confidence band is appended to the finished product.
Encoding Uncertainty in OGC Services: The UncertWeb Approach
The UncertWeb project developed a set of uncertainty profile extensions for standard OGC web services intended to close this gap. The core design philosophy was conservative: do not invent new service types; instead extend existing standards at the data model layer so that uncertainty-aware clients can exploit the additional information while legacy clients continue to receive standard responses.
Three encoding patterns were defined for different use cases:
Inline uncertainty encoding embeds uncertainty information directly in the coverage or feature response. For a raster coverage, a companion band carries the per-pixel uncertainty estimate. The band’s semantics (whether it represents a standard deviation, a 90th-percentile half-width, or a qualitative quality class) are declared in the coverage metadata. This pattern is the most backward-compatible and the most widely deployable with existing software infrastructure.
Ensemble encoding returns a collection of equally-plausible realizations of the output field rather than a single best estimate. Each realization is a complete coverage object, and the ensemble together spans the uncertainty distribution. This pattern is better suited to non-Gaussian uncertainties and to applications that need to propagate uncertainty correctly through subsequent non-linear processing steps. The cost is that payload size scales linearly with ensemble size.
Distribution parameter encoding encodes the parameters of a named probability distribution (mean and variance for a Gaussian, alpha and beta for a Beta distribution) at each location. This is compact and analytically tractable but requires choosing a distributional family in advance, which is a modeling assumption that may not hold everywhere in the domain.
A processing service declares which encoding patterns it can accept as input and which it produces as output in its WPS capabilities document. An orchestration layer (a workflow engine or a catalog-aware client) can then inspect these declarations and route data through a chain such that the encoding type is compatible at each step.
Capability Discovery and Automated Chain Composition
One of the more ambitious goals of the UncertWeb architecture was automated chain composition: the ability for a software agent to query a service registry, find services capable of processing uncertainty-encoded inputs, and assemble them into a valid workflow without manual configuration.
This requires two capabilities beyond what base OGC standards provide. First, services must declare their uncertainty handling behavior in machine-readable form in their capabilities documents: specifically, the type of uncertainty encoding each input parameter accepts and each output delivers. Second, a reasoning component must be able to match output types to input requirements and identify compatible compositions.
The UncertWeb project implemented both components. Uncertainty capability annotations were added to WPS process descriptions using an agreed XML schema. A prototype orchestration service was built that could query a registry of annotated services and produce a candidate workflow graph for a user-specified processing objective. Evaluated against case studies in air quality modeling and hydrological forecasting, the prototype demonstrated that end-to-end uncertainty propagation through a three- to four-service chain was achievable within the GEOSS framework.
Practical Integration with Existing Data Infrastructure
The theoretical architecture of uncertainty-aware service chains is useful only if it can be implemented alongside (not instead of) existing operational data infrastructure. Most operational geospatial data systems are built around formats and conventions that predate the UncertWeb uncertainty encoding work: GeoTIFF files with no uncertainty companion, NetCDF archives with rudimentary quality flags, WMS services designed exclusively for visualization.
A pragmatic integration strategy proceeds incrementally. At the production stage, processing algorithms that already compute uncertainty internally (radiometric calibration routines, statistical interpolation algorithms, ensemble numerical weather prediction systems) are modified to write uncertainty outputs alongside primary outputs using an agreed encoding. NetCDF-CF’s ancillary_variables convention is a practical starting point that is already supported by major analysis toolchains including xarray, GDAL, and QGIS.
At the service layer, WCS and WPS implementations are updated to expose the uncertainty companion fields when queried by uncertainty-aware clients. The additional capability is advertised in the capabilities document. Legacy clients receive the same primary data they always have.
At the catalog layer, ISO 19115 metadata records for datasets are extended to document the uncertainty model: which components are tracked, what distributional assumptions are made, what validation has been performed. This documentation is the minimum provenance required for a downstream service to correctly interpret an uncertainty encoding.
JavaScript Statistical Tools for Lightweight UQ in Web Applications
Not all UQ needs to happen in a heavy server-side processing pipeline. Web-based visualization and analysis tools increasingly need to compute summary statistics (confidence intervals, kernel density estimates, quantiles) on data retrieved from web services. The jStat library, developed partly in connection with the UncertWeb project, provides a comprehensive set of statistical distributions and numerical methods in pure JavaScript, enabling these computations in browser or Node.js environments without a round-trip to a server.
For lightweight UQ tasks (computing a confidence interval on a sample of ensemble members retrieved from a WPS service, or visualizing a probability density function encoded in a distribution parameter response), jStat removes the dependency on a server-side Python or R environment. This is particularly useful for client-side applications that need to display uncertainty information interactively.
Cross-References
This article connects to the broader UncertWeb topic areas on this site. For the foundational methods used to quantify uncertainty before it is encoded in service responses, see the article on quantifying uncertainty in spatial environmental models. For the architecture of the model web that these services are designed to compose within, see the article on the model web architecture for global earth observation.